맵(Map)은 키-값 쌍을 저장하는 추상 자료형(ADT)으로, 같은 키를 가진 쌍은 최대 하나만 존재합니다. 전화번호와 이름, 단어와 빈도수, 사용자 ID와 프로필처럼 "키로 값을 찾는" 모든 곳에 쓰입니다.
해시 테이블은 Map을 구현한 자료구조 중 가장 흔히 쓰이는 형태로, 해시 함수를 통해 키를 배열의 인덱스로 변환해 평균 $O(1)$ 시간에 데이터에 접근합니다. Python의 dict, Java의 HashMap, C++의 unordered_map이 모두 해시 테이블 기반입니다.

핵심 개념
- 해시 함수(Hash Function): 키를 배열 인덱스로 변환하는 함수
- 버킷(Bucket): 해시 테이블의 각 슬롯
- 해시 충돌(Hash Collision): 서로 다른 키가 같은 인덱스로 해시되는 현상
- 로드 팩터(Load Factor): 저장된 원소 수 / 테이블 크기
해시 함수
좋은 해시 함수의 조건
- 균등 분포: 키들이 테이블 전체에 고르게 분산
- 빠른 계산: $O(1)$ 시간에 계산 가능
- 결정적: 같은 키는 항상 같은 값 반환
일반적인 해시 함수들
def division_hash(key, table_size):
"""나눗셈 해시"""
return key % table_size
def multiplication_hash(key, table_size):
"""곱셈 해시"""
A = 0.6180339887 # (√5 - 1) / 2
return int(table_size * ((key * A) % 1))
def string_hash(s, table_size):
"""문자열 해시 (djb2 알고리즘)"""
hash_value = 5381
for char in s:
hash_value = ((hash_value << 5) + hash_value) + ord(char)
return hash_value % table_size
def polynomial_hash(s, table_size):
"""다항식 해시"""
p = 31 # 소수
hash_value = 0
p_pow = 1
for char in s:
hash_value = (hash_value + ord(char) * p_pow) % table_size
p_pow = (p_pow * p) % table_size
return hash_value참고 영상
해시 테이블의 동작 — 키-밸류 저장, 해시 충돌, 체이닝·선형 탐사, 리사이징 — 은 그림으로 보면 한 번에 잡힙니다.
맵(Map)과 해시 테이블(Hash Table) 핵심만 모아보기 (YouTube)
충돌 해결 방법
1. 개별 체이닝 (Separate Chaining)
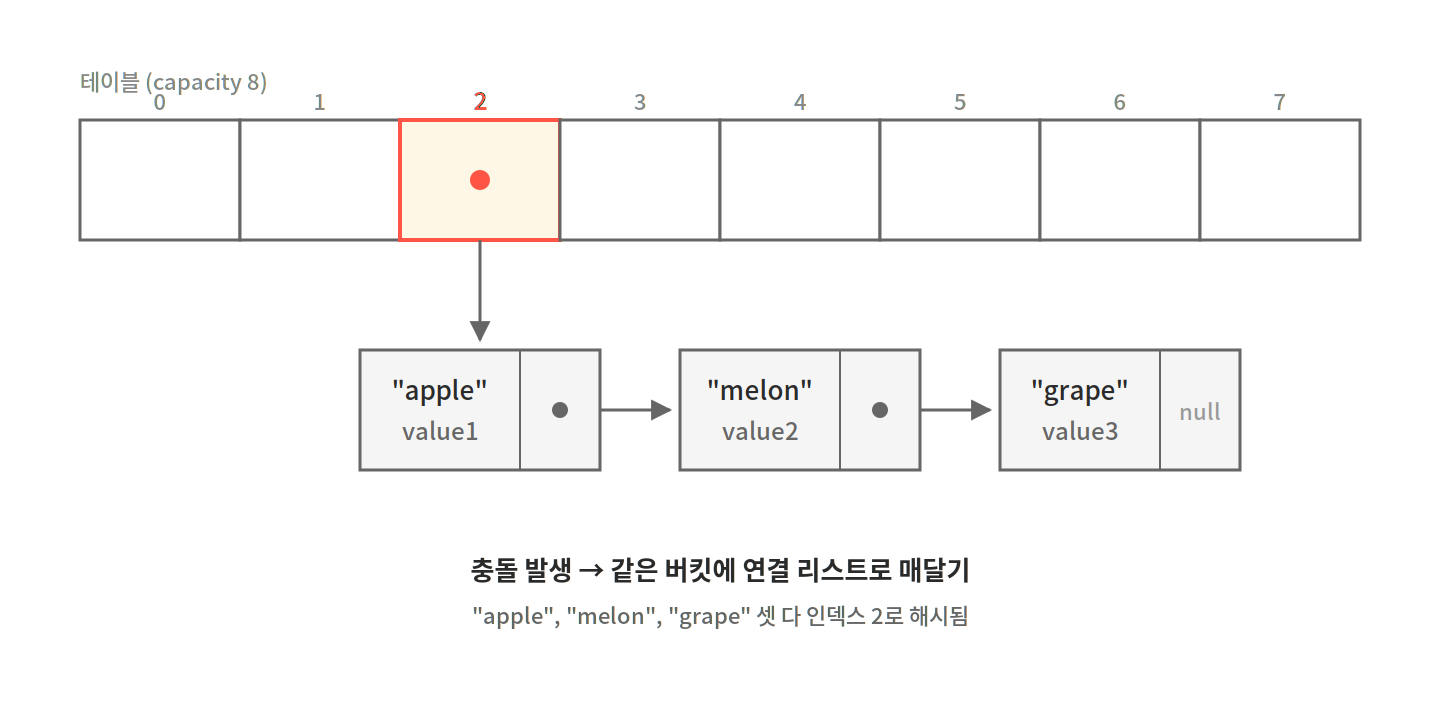
같은 인덱스로 해시되는 키들을 연결 리스트로 묶어 한 버킷에 함께 저장합니다. 충돌이 발생해도 테이블 외부에 데이터를 매달 수 있어 로드 팩터가 1을 넘어도 동작하지만, 한 버킷의 리스트가 길어지면 검색 시간이 그만큼 늘어나는 것이 단점입니다.
class Node:
"""체이닝용 연결 리스트 노드"""
def __init__(self, key, value):
self.key = key
self.value = value
self.next = None
class HashTableChaining:
def __init__(self, size=10):
self.size = size
self.table = [None] * size # 각 슬롯이 연결 리스트의 head
self.count = 0
def _hash(self, key):
"""해시 함수"""
if isinstance(key, str):
return sum(ord(c) for c in key) % self.size
return key % self.size
def put(self, key, value):
"""키-값 쌍 삽입"""
index = self._hash(key)
node = self.table[index]
# 기존 키가 있는지 확인
while node is not None:
if node.key == key:
node.value = value # 값 업데이트
return
node = node.next
# 새 노드를 리스트 맨 앞에 삽입 (head insertion)
new_node = Node(key, value)
new_node.next = self.table[index]
self.table[index] = new_node
self.count += 1
def get(self, key):
"""값 조회"""
index = self._hash(key)
node = self.table[index]
while node is not None:
if node.key == key:
return node.value
node = node.next
raise KeyError(f"Key '{key}' not found")
def delete(self, key):
"""키-값 쌍 삭제"""
index = self._hash(key)
node = self.table[index]
prev = None
while node is not None:
if node.key == key:
if prev is None:
self.table[index] = node.next # 첫 번째 노드 삭제
else:
prev.next = node.next
self.count -= 1
return node.value
prev = node
node = node.next
raise KeyError(f"Key '{key}' not found")
def load_factor(self):
"""로드 팩터 계산"""
return self.count / self.size
def display(self):
"""테이블 출력"""
for i in range(self.size):
node = self.table[i]
if node is not None:
items = []
while node is not None:
items.append(f"({node.key}, {node.value})")
node = node.next
print(f"Bucket {i}: {' -> '.join(items)}")2. 개방 주소법 (Open Addressing)
충돌이 발생하면 같은 테이블 안에서 다른 빈 슬롯을 찾아 거기에 저장합니다. 외부 자료구조 없이 배열만으로 동작하지만, 로드 팩터가 1을 넘을 수 없고 데이터가 특정 영역에 뭉치는 클러스터링 문제가 생깁니다. 빈 슬롯을 찾아가는 방식(탐사 함수)에 따라 선형 탐사·이차 탐사·더블 해싱으로 나뉩니다.
선형 탐사 (Linear Probing)

충돌이 일어난 인덱스의 바로 다음 칸(+1)부터 차례로 빈 슬롯을 찾습니다. 구현이 가장 간단하지만, 충돌이 모인 위치 주변에 데이터가 길게 늘어붙는 1차 클러스터링이 발생해 점점 검색이 느려집니다.
class HashTableLinearProbing:
def __init__(self, size=10):
self.size = size
self.keys = [None] * size
self.values = [None] * size
self.count = 0
def _hash(self, key):
if isinstance(key, str):
return sum(ord(c) for c in key) % self.size
return key % self.size
def _probe(self, key):
"""선형 탐사로 빈 슬롯 또는 키 위치 찾기"""
index = self._hash(key)
original_index = index
while self.keys[index] is not None:
if self.keys[index] == key:
return index
index = (index + 1) % self.size
# 테이블이 가득 찬 경우
if index == original_index:
raise Exception("Hash table is full")
return index
def put(self, key, value):
if self.count >= self.size:
raise Exception("Hash table is full")
index = self._probe(key)
# 새로운 키인 경우
if self.keys[index] is None:
self.count += 1
self.keys[index] = key
self.values[index] = value
def get(self, key):
index = self._hash(key)
original_index = index
while self.keys[index] is not None:
if self.keys[index] == key:
return self.values[index]
index = (index + 1) % self.size
if index == original_index:
break
raise KeyError(f"Key '{key}' not found")
def delete(self, key):
index = self._hash(key)
original_index = index
while self.keys[index] is not None:
if self.keys[index] == key:
value = self.values[index]
self.keys[index] = None
self.values[index] = None
self.count -= 1
# 삭제 후 재해싱 (클러스터링 방지)
self._rehash_after_delete(index)
return value
index = (index + 1) % self.size
if index == original_index:
break
raise KeyError(f"Key '{key}' not found")
def _rehash_after_delete(self, deleted_index):
"""삭제 후 클러스터링 해결을 위한 재해싱"""
index = (deleted_index + 1) % self.size
while self.keys[index] is not None:
key_to_rehash = self.keys[index]
value_to_rehash = self.values[index]
self.keys[index] = None
self.values[index] = None
self.count -= 1
self.put(key_to_rehash, value_to_rehash)
index = (index + 1) % self.size이차 탐사 (Quadratic Probing)
충돌 시 +1, +4, +9, +16... 처럼 제곱수만큼 떨어진 위치를 탐사합니다. 선형 탐사의 1차 클러스터링은 완화되지만, 같은 인덱스로 해시된 키들은 같은 경로를 따라가는 2차 클러스터링이 남습니다.
class HashTableQuadraticProbing:
def __init__(self, size=10):
self.size = size
self.keys = [None] * size
self.values = [None] * size
self.count = 0
def _hash(self, key):
if isinstance(key, str):
return sum(ord(c) for c in key) % self.size
return key % self.size
def _probe(self, key):
"""이차 탐사로 빈 슬롯 또는 키 위치 찾기"""
index = self._hash(key)
original_index = index
i = 0
while self.keys[index] is not None:
if self.keys[index] == key:
return index
i += 1
index = (original_index + i * i) % self.size
# 무한 루프 방지
if i >= self.size:
raise Exception("Hash table is full or cannot find slot")
return index
def put(self, key, value):
if self.count >= self.size:
raise Exception("Hash table is full")
index = self._probe(key)
if self.keys[index] is None:
self.count += 1
self.keys[index] = key
self.values[index] = value더블 해싱 (Double Hashing)

두 번째 해시 함수의 결과만큼 점프하면서 탐사합니다. 키마다 점프 폭이 달라지기 때문에 1차·2차 클러스터링이 모두 줄어드는 대신, 해시 함수를 두 번 계산해야 하는 비용이 있습니다.
class HashTableDoubleHashing:
def __init__(self, size=10):
self.size = size
self.keys = [None] * size
self.values = [None] * size
self.count = 0
def _hash1(self, key):
"""첫 번째 해시 함수"""
if isinstance(key, str):
return sum(ord(c) for c in key) % self.size
return key % self.size
def _hash2(self, key):
"""두 번째 해시 함수"""
if isinstance(key, str):
hash_val = sum(ord(c) for c in key)
else:
hash_val = key
return 7 - (hash_val % 7) # 7은 테이블 크기보다 작은 소수
def _probe(self, key):
"""더블 해싱으로 빈 슬롯 또는 키 위치 찾기"""
index = self._hash1(key)
step = self._hash2(key)
original_index = index
while self.keys[index] is not None:
if self.keys[index] == key:
return index
index = (index + step) % self.size
if index == original_index:
raise Exception("Hash table is full")
return index
def put(self, key, value):
if self.count >= self.size:
raise Exception("Hash table is full")
index = self._probe(key)
if self.keys[index] is None:
self.count += 1
self.keys[index] = key
self.values[index] = value동적 리사이징

데이터가 일정 비율 이상 차면(보통 로드 팩터 0.75 전후) 테이블 크기를 두 배로 늘리고 모든 원소를 새 크기에 맞춰 다시 해시합니다. 테이블이 좁아져서 충돌이 잦아지는 문제를 근본적으로 해결하는 방법이며, 충돌 해결 방식과 무관하게 함께 쓰입니다. 줄이는 방향도 가능해서 데이터가 빠진 뒤 일정 수준 이하가 되면 크기를 줄이기도 합니다.
class ResizableHashTable:
def __init__(self, initial_size=8):
self.size = initial_size
self.table = [[] for _ in range(self.size)]
self.count = 0
def _hash(self, key):
if isinstance(key, str):
return sum(ord(c) for c in key) % self.size
return key % self.size
def _resize(self, new_size):
"""테이블 크기 조정"""
old_table = self.table
self.size = new_size
self.table = [[] for _ in range(self.size)]
old_count = self.count
self.count = 0
# 모든 원소를 새 테이블에 재삽입
for bucket in old_table:
for key, value in bucket:
self.put(key, value)
def put(self, key, value):
# 로드 팩터가 0.75를 초과하면 크기 두 배로 증가
if self.count / self.size > 0.75:
self._resize(self.size * 2)
index = self._hash(key)
bucket = self.table[index]
for i, (k, v) in enumerate(bucket):
if k == key:
bucket[i] = (key, value)
return
bucket.append((key, value))
self.count += 1
def delete(self, key):
index = self._hash(key)
bucket = self.table[index]
for i, (k, v) in enumerate(bucket):
if k == key:
del bucket[i]
self.count -= 1
# 로드 팩터가 0.25 미만이면 크기 절반으로 감소
if self.count / self.size < 0.25 and self.size > 8:
self._resize(self.size // 2)
return v
raise KeyError(f"Key '{key}' not found")시간복잡도
| 연산 | 평균 | 최악 |
|---|---|---|
| 삽입 | $O(1)$ | $O(n)$ |
| 삭제 | $O(1)$ | $O(n)$ |
| 검색 | $O(1)$ | $O(n)$ |
활용 예시
1. 단어 빈도 계산
def word_frequency(text):
word_count = {}
words = text.lower().split()
for word in words:
word_count[word] = word_count.get(word, 0) + 1
return word_count
text = "hello world hello python world"
print(word_frequency(text)) # {'hello': 2, 'world': 2, 'python': 1}2. 두 수의 합 찾기
def two_sum(nums, target):
"""두 수의 합이 target인 인덱스 찾기"""
num_to_index = {}
for i, num in enumerate(nums):
complement = target - num
if complement in num_to_index:
return [num_to_index[complement], i]
num_to_index[num] = i
return []
nums = [2, 7, 11, 15]
target = 9
print(two_sum(nums, target)) # [0, 1]3. 그룹 애너그램
def group_anagrams(strs):
"""애너그램끼리 그룹화"""
anagram_groups = {}
for s in strs:
# 정렬된 문자열을 키로 사용
key = ''.join(sorted(s))
if key not in anagram_groups:
anagram_groups[key] = []
anagram_groups[key].append(s)
return list(anagram_groups.values())
strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
print(group_anagrams(strs)) # [['eat', 'tea', 'ate'], ['tan', 'nat'], ['bat']]4. LRU 캐시 (해시 테이블 + 연결 리스트)

class Node:
"""이중 연결 리스트 노드"""
def __init__(self, key=None, value=None):
self.key = key
self.value = value
self.prev = None
self.next = None
class LRUCache:
def __init__(self, capacity):
self.capacity = capacity
self.cache = {} # 해시 테이블: key -> Node
# dummy head/tail로 경계 조건 단순화
self.head = Node()
self.tail = Node()
self.head.next = self.tail
self.tail.prev = self.head
def _add_to_front(self, node):
"""노드를 head 직후에 삽입 (가장 최근)"""
node.prev = self.head
node.next = self.head.next
self.head.next.prev = node
self.head.next = node
def _remove(self, node):
"""노드를 리스트에서 제거"""
node.prev.next = node.next
node.next.prev = node.prev
def get(self, key):
if key not in self.cache:
return -1
node = self.cache[key]
# 최근 접근이므로 맨 앞으로 이동
self._remove(node)
self._add_to_front(node)
return node.value
def put(self, key, value):
if key in self.cache:
# 기존 키: 값 업데이트 + 맨 앞으로
node = self.cache[key]
node.value = value
self._remove(node)
self._add_to_front(node)
else:
# 새 키
if len(self.cache) >= self.capacity:
# 용량 초과: tail 직전 노드 (가장 오래된 것) 제거
lru = self.tail.prev
self._remove(lru)
del self.cache[lru.key]
new_node = Node(key, value)
self.cache[key] = new_node
self._add_to_front(new_node)해시 테이블 vs 다른 자료구조
| 자료구조 | 검색 시간 | 삽입 시간 | 삭제 시간 | 메모리 사용량 | 순서 유지 |
|---|---|---|---|---|---|
| 해시 테이블 | $O(1)$ avg | $O(1)$ avg | $O(1)$ avg | 높음 | 없음 |
| 배열 | $O(n)$ | $O(n)$ | $O(n)$ | 낮음 | 있음 |
| 연결 리스트 | $O(n)$ | $O(1)$ | $O(1)$ | 중간 | 있음 |
| 이진 탐색 트리 | $O(\log n)$ | $O(\log n)$ | $O(\log n)$ | 중간 | 있음 |
장단점
장점
- 빠른 연산: 평균 $O(1)$ 시간복잡도
- 유연한 키: 다양한 데이터 타입을 키로 사용 가능
- 동적 크기: 필요에 따라 크기 조정 가능
- 메모리 효율적: 필요한 만큼만 공간 사용
단점
- 순서 없음: 삽입 순서나 정렬 순서 보장 안됨
- 해시 충돌: 성능 저하 원인
- 메모리 오버헤드: 추가 공간 필요
- 최악의 경우: $O(n)$ 시간복잡도 가능
실제 활용 분야
- 데이터베이스: 인덱싱, 조인 연산
- 캐싱: 웹 캐시, CPU 캐시
- 컴파일러: 심볼 테이블, 변수 관리
- 네트워크: 라우팅 테이블, DNS
- 보안: 패스워드 저장, 체크섬
- 빅데이터: 분산 해싱, 샤딩
Map과 해시 테이블의 관계
Map은 ADT(Abstract Data Type)다. 키-값 매핑이라는 동작 인터페이스만 정의할 뿐, 어떻게 구현하는지는 명시하지 않는다. 해시 테이블은 그 Map을 구현한 데이터 구조이며, 트리 기반(Red-Black Tree 같은) 방식으로도 Map을 구현할 수 있다. 해시 테이블이 사실상 표준처럼 쓰이는 이유는 평균 O(1) 접근 성능이다. 다만 충돌 해결 방식은 언어마다 다르다 — Python의
dict는 개방 주소법, Java의HashMap은 체이닝을 쓴다 (JDK 8부터는 한 버킷의 노드가 일정 수를 넘으면 Red-Black Tree로 전환한다).
'DSA' 카테고리의 다른 글
| 우선순위 큐(Priority Queue)와 힙(Heap) (0) | 2026.05.24 |
|---|---|
| 정렬(Sorting) 알고리즘 6가지 — 원리·복잡도·선택 가이드 (0) | 2026.05.24 |