들어가며
3편에서 메커니즘이 완성됐다. 스왑 공간이 있고, present bit으로 페이지 부재를 표시하고, 페이지 폴트가 발생하면 OS 핸들러가 디스크에서 가져온다. 메모리가 가득 차면 기존 페이지 하나를 내보내고 새 페이지를 들인다.
남은 질문은 하나다 — 어떤 페이지를 내보내야 하는가. 이 결정이 페이지 교체 정책(page replacement policy) 이고, 이번 편의 주제다.
이 선택의 무게는 가상 메모리에서 가장 크다. 페이지가 메모리에 있으면 접근에 약 100ns, 디스크로 내려가면 약 10ms — 약 10⁵배 차이다. 잘못 내보내서 다시 폴트가 나면 그 한 번에 명령어 수십만 개를 실행할 시간을 잃는다. 정책이 좋으면 시스템은 메모리 속도로 돌고, 나쁘면 디스크 속도로 떨어진다.
3편에서 짚었듯, 가상 메모리는 캐싱이다. 메모리는 디스크의 캐시고, 정책은 "캐시에 무엇을 둘 것인가"를 결정한다. 4편 본문은 이 캐싱 관점에서 정책을 정량적으로 본다. 그러기 위해 먼저 얼마나 좋은 정책인지 측정할 도구가 필요하다.
캐싱의 정량 — AMAT
평균 메모리 접근 시간 — AMAT(Average Memory Access Time) — 은 캐싱이 얼마나 잘 동작하는지를 나타낸다.
$$AMAT = T_M + (P_{Miss} \cdot T_D)$$
- $T_M$: 메모리 접근 시간 (≈ 100ns)
- $T_D$: 디스크 접근 시간 (≈ 10ms)
- $P_{Miss}$: 미스율 (페이지가 메모리에 없을 확률)

메모리에서 페이지를 찾으면 $T_M$만 든다. 디스크로 내려가야 하면 $T_D$가 추가로 든다 — 그것도 매번이 아니라 미스율 확률만큼. 정책의 임무는 미스율을 최소화하는 것이다.
수치 감을 잡아 보면 — $T_M = 100ns$, $T_D = 10ms$일 때:
| 미스율 | AMAT | 메모리 속도 대비 |
|---|---|---|
| 10% | 약 1ms | 10,000배 느림 |
| 1% | 약 100μs | 1,000배 느림 |
| 0.1% | 약 10.1μs | 100배 느림 |
| 0.01% | 약 1.1μs | 10배 느림 |
| 0% | 100ns | 동일 |
미스율을 한 자릿수 줄이는 것이 성능을 한 자릿수 끌어올린다. 1%가 좋아 보여도 메모리 속도 대비 1,000배 느림이다. 캐시 미스가 얼마나 비싼지가 이 표의 핵심이다.
이상적 기준 — 최적 정책
정책의 얼마나 좋은지를 평가하려면 상한선이 필요하다. 1966년 Belady가 제시한 최적 정책(OPT, Optimal) 이 그 역할을 한다.
규칙은 단순하다 — 미래에 가장 멀리 다시 쓰일 페이지를 축출한다. 직관도 단순하다. 캐시에 남은 페이지들이 제거된 페이지보다 더 빨리 필요하다는 보장이 생긴다.
수학적으로 OPT는 미스율을 최소화하는 게 증명된 알고리즘이다. 그런데 실용성은 0이다(미래를 알아야 하기 때문). 일반적인 OS는 미래의 접근 패턴을 모른다.
그럼 왜 다루는가? 다른 정책의 채점 기준이다. 80% 히트율이라는 수치는 그 자체로는 의미가 옅다 — OPT가 82%인 워크로드에서 80%면 거의 최적이고, OPT가 95%인 워크로드에서 80%면 멀었다는 뜻이다. 얼마나 떨어졌는지를 측정하기 위해 OPT를 시뮬레이션으로 돌려 비교한다.
단순 정책 — FIFO, Random
미래를 모르니 과거나 우연에 의존한다. 가장 단순한 두 정책이 FIFO와 Random이다.
FIFO(First-In, First-Out) — 큐를 두고 가장 먼저 들어온 페이지를 가장 먼저 내보낸다. 구현이 거의 무료 — 큐의 head·tail 포인터 두 개만 있으면 된다. 캐시 히트가 나도 큐 순서를 건드리지 않는다. 페이지가 언제 들어왔는지만 본다.
Random — 그냥 무작위로 고른다. 의사난수 생성기 하나면 된다. 메타데이터 0, 결정 비용 0. 운에 맡기는 정책이다.

3페이지 캐시에 접근 시퀀스 0, 1, 2, 0, 1, 3, 0, 3, 1, 2, 1을 흘려 보면 — OPT는 6 히트, FIFO는 4 히트, LRU(Least Recently Used, 다음 절에서 다룬다)도 6 히트, Random은 평균 5 히트 수준이다. 11개 접근의 작은 예제지만 정책의 결의 차이가 드러난다.
FIFO의 문제는 명확하다 — 최근에 사용된 페이지도 진입 순서만으로 축출된다. 위 예제에서 페이지 0이 직전에 사용됐는데 FIFO는 "가장 먼저 들어왔다"는 이유로 0을 내보낸다. 직후에 다시 0이 필요해지므로 미스. 시간적 지역성을 전혀 활용하지 않는 정책의 대가다.
Belady의 이상 현상
FIFO에는 또 하나의 결함이 있다. 1969년 Belady가 발견한 사실 — 캐시 크기를 늘렸는데 미스율이 오히려 증가하는 워크로드가 존재한다. 더 큰 캐시는 더 많은 페이지를 담으니 미스가 줄어야 한다는 직관에 정면으로 반한다.
이 이상 현상은 정책이 스택 속성을 만족하지 않을 때 생긴다. 스택 속성이란 "크기 N+1 캐시의 내용이 항상 크기 N 캐시의 내용을 포함한다"는 성질이다. LRU와 OPT는 이 속성을 만족하고, FIFO와 Random은 위반한다. 즉 FIFO에서는 캐시가 커져도 *완전히 다른 페이지 집합*이 들어 있을 수 있고, 그래서 캐시 크기와 성능이 반드시 비례하지 않는다.
실용적 함의 — 메모리를 늘렸는데 성능이 떨어진다는 의외의 보고는 정책의 스택 속성 위반에서 올 수 있다. 그래서 현대 시스템의 페이지 교체 정책은 거의 스택 속성을 만족하는 LRU 계열을 쓴다.
Random은 의외로 평균적으로 FIFO보다 나쁘지 않다 — 운이 좋으면 OPT와 같고, 운이 나빠도 FIFO 같은 결정적으로 잘못된 패턴에 빠지지는 않는다. 10,000번 시뮬레이션을 돌리면 약 40%의 실행에서 OPT와 동일한 성능에 도달한다는 결과도 있다. 다만 예측 불가능하다는 게 운영 시스템에서는 단점이 된다 — 같은 입력에 같은 성능을 보장하지 못한다.
히스토리로 미래를 추측한다 — LRU

미래를 모르면 과거가 다음으로 좋은 정보다. 그리고 과거에서 미래를 추측할 수 있는 근거가 — 지역성(locality) 이다.
지역성은 1970년 Denning이 정리한 관찰로, 프로그램이 최근에 접근한 페이지나 그 주변 페이지를 곧 다시 접근하는 경향을 가리킨다. 루프, 자주 호출되는 함수, 핫한 데이터 구조 — 모두 같은 페이지에 반복 접근하는 패턴이다. 지역성은 보장되는 법칙이 아니지만 경향으로는 강력해, 거의 모든 정책의 토대다.
지역성을 이용하는 가장 직관적인 정책이 LRU다 — 가장 오래 안 쓴 페이지를 축출한다. 최근에 안 쓴 페이지는 앞으로도 안 쓸 가능성이 높다는 가정이다.
각 페이지마다 마지막으로 접근한 시각을 기록해 두고, 축출이 필요하면 그 값이 가장 오래된 페이지를 고른다. 캐시 히트가 나도 — FIFO와 달리 — 그 페이지의 시각을 갱신한다. 즉 자주 쓰이는 페이지는 계속 최신화되어 축출 대상에서 멀어진다.
위의 11개 접근 예제에서 LRU는 6 히트로 OPT와 동일하다. 우연이 아니다. 그 시퀀스에는 지역성이 충분히 있어서, 과거 정보만으로도 최적의 결정이 가능했다. 대부분의 실제 워크로드도 비슷한 결을 띤다.
LRU 계열에는 LFU(Least Frequently Used) — 가장 적게 쓴 페이지 축출 — 도 있다. 빈도를 본다는 점에서 LRU와 결이 다른데, 둘 다 지역성을 양의 방향으로 활용한다. 반대로 MRU·MFU 같은 정책도 정의는 가능하지만 — 가장 최근에 쓴 페이지나 가장 자주 쓴 페이지를 축출 — 지역성에 반하므로 일반 상황에선 비효율적이다.
워크로드가 정책을 결정한다
LRU가 항상 OPT에 근접하느냐 하면 그렇지는 않다. 워크로드에 따라 정책의 성능이 극단적으로 갈린다.

세 가지 워크로드를 보면 그림이 분명해진다.
워크로드 1 — 지역성이 없을 때: 100개의 페이지를 완전히 무작위로 10,000번 접근하는 패턴. 결과는 단순하다 — 모든 정책이 같은 성능. 지역성이 없으니 과거 정보가 의미가 없고, 정책이 무엇이든 캐시 크기에만 비례해 히트율이 올라간다. 캐시가 100페이지가 되면 모든 정책이 100% 히트율. 지역성이 없으면 정책을 정교화해도 소득이 없다.
워크로드 2 — 80-20 패턴: 페이지의 20%(핫 페이지)에 접근의 80%가 몰리고, 나머지 80%(콜드 페이지)에 20%가 흩어지는 워크로드. 파레토 법칙의 컴퓨터 버전이고 실제 애플리케이션에서 매우 흔하다. 여기서 LRU가 빛난다 — 핫 페이지가 자주 접근되니 LRU의 최근 사용 추적이 그것을 자동으로 잡아낸다. FIFO·Random은 진입 순서나 운에 따라 핫 페이지도 그대로 내보내, 의미 있게 떨어진다.
워크로드 3 — 루핑 순차 접근: 페이지 0, 1, ..., 49를 순서대로 접근한 뒤 다시 0부터 반복하는 패턴. 데이터베이스의 테이블 스캔이나 큰 배열의 반복 처리 같은 데서 흔하다. 이 워크로드에서 — 캐시 크기가 49페이지라고 가정하면 — LRU와 FIFO의 히트율이 0%다. 캐시에 페이지 0~48이 들어 있는 상태에서 페이지 49가 필요해지면, LRU는 "가장 오래 안 쓴" 페이지 0을 축출한다. 그러나 다음 루프에서 페이지 0이 가장 먼저 필요하다. 매번 정확히 다음에 필요한 페이지를 내보내는 — 최악의 패턴이다.
이 워크로드에서는 Random이 상대적으로 낫다. 운이 좋으면 다음에 필요한 페이지를 보존할 수도 있어 0%는 면한다. 일반적으로 단순한 정책에 밀리는 Random이 이런 코너 케이스에서는 이긴다 — 편향이 없다는 게 그래서 강점이 되기도 한다.
이 셋이 시사하는 바는 분명하다 — 만능 정책은 없다. 지역성이 없으면 캐시 크기만 의미 있고, 지역성이 있으면 LRU 계열이 우월하며, 특정 코너 케이스에서는 단순 정책이 외려 낫다. 그래서 현대 시스템은 LRU를 기본으로 두되 루핑 시퀀스 같은 패턴에 대한 방어를 함께 갖는다 — 뒤에서 다룰 ARC 등이 그런 방향의 진화다.
LRU의 구현 비용과 Clock 근사
LRU는 원리가 깔끔한데 구현이 깔끔하지 않다. 모든 메모리 접근마다 — 즉 명령어 인출, 데이터 읽기, 데이터 쓰기 각각에 대해 — 해당 페이지의 최근 접근 시각을 갱신해야 한다. 4GB 메모리에 4KB 페이지면 페이지가 약 100만 개고, 그 중 어느 페이지가 가장 오래됐는지를 빠르게 찾는 자료구조도 필요하다.
하드웨어 지원을 받아도 부담은 크다. 각 페이지에 타임스탬프 필드를 두고 접근마다 갱신하는 방식이 가능하지만, 축출 결정 시 100만 개의 타임스탬프를 다 살피는 일은 현실적이지 않다. 완벽한 LRU는 비용 대비 가치가 떨어진다.
그래서 실제 시스템은 LRU를 근사한다. 가장 널리 쓰는 근사가 Clock 알고리즘이다. 1969년 Corbato가 제안했고, 거의 LRU만큼의 성능을 훨씬 적은 비용에 낸다.
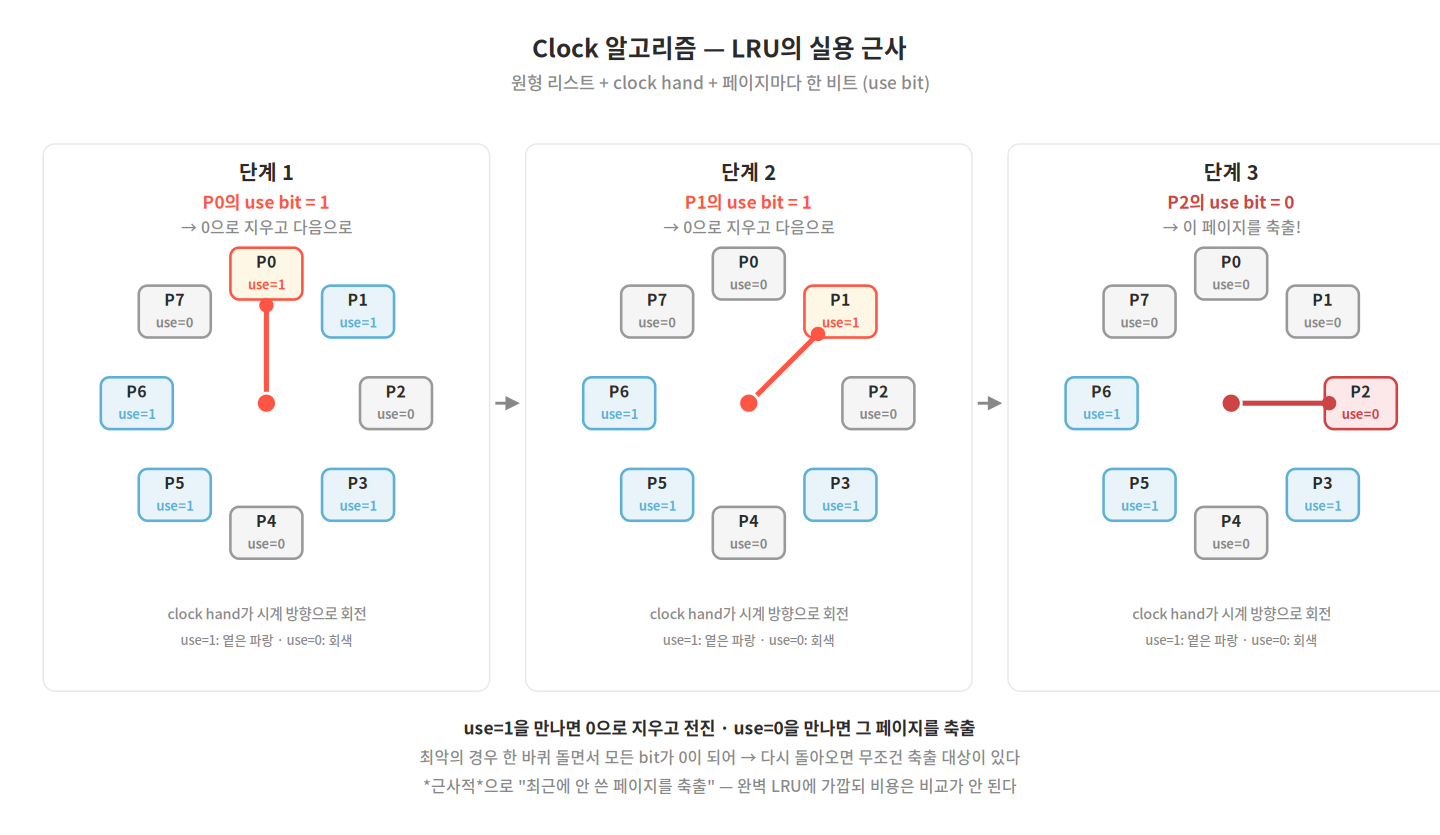
핵심 부품은 두 가지다.
- reference bit(또는 use bit): 페이지마다 한 비트. 페이지에 접근하면 하드웨어가 자동으로 1로 설정한다. OS는 이 비트를 0으로 지우는 일만 한다.
- clock hand: 페이지들을 원형 리스트로 두고, 그 위를 도는 포인터. 축출 결정 시 현재 위치에서 시작해 한 칸씩 전진하며 reference bit를 검사한다.
알고리즘은 단순하다. 축출이 필요하면 clock hand가 가리키는 페이지의 reference bit를 본다.
- 1이면 — "최근에 쓴 페이지다" — 축출하지 않고 0으로 지운 뒤 다음 페이지로 hand를 이동.
- 0이면 — "최근에 안 쓴 페이지다" — 그 페이지를 축출.
지나가면서 0으로 지운 페이지가 다시 hand에 도달했을 때 여전히 0이면 (그동안 안 쓰였다는 뜻) 축출 대상이 된다. 결과적으로 최근에 안 쓰인 페이지가 우선 축출되는 — LRU와 거의 같은 결정이다. 다만 정확히 가장 오래된 페이지가 아니라 그 근처의 페이지를 고른다는 점이 다르다.
비용은 비교가 안 된다. 모든 접근에 대해 시각 갱신이 아니라 비트 한 개 설정만 — 그것도 하드웨어가 자동으로. OS는 축출 시점에 hand를 몇 칸 전진하면 그만이다. 거의 무료 수준이고, 성능은 완벽 LRU에 매우 근접한다. 대부분의 현대 OS가 Clock 또는 그 변형을 쓴다.
더 절약하기 — Dirty 페이지 고려
Clock의 또 한 차원 개선은 축출 비용 자체의 차이에서 나온다. 페이지를 축출할 때 두 경우가 있다.
- Clean 페이지 — 메모리에 적재된 뒤 수정되지 않은 페이지. 디스크의 원본과 동일하므로 그냥 메모리에서 지우면 끝. 추가 I/O 0.
- Dirty 페이지 — 메모리에서 수정된 페이지. 디스크에 다시 써야(write-back) 데이터를 잃지 않는다. 추가 디스크 I/O 발생.
같은 최근에 안 쓴 페이지 두 개 중에서 — 하나는 clean이고 하나는 dirty라면 — clean을 축출하는 게 훨씬 싸다. 한 번의 디스크 쓰기를 절약한다.
이걸 지원하려면 또 한 비트가 필요하다 — dirty bit(또는 modified bit). 페이지에 쓰기가 일어나면 하드웨어가 자동으로 1로 설정한다. 읽기만 일어났으면 0 그대로.
Clock 알고리즘의 스캔 순서가 두 단계로 확장된다.
- 1순위 스캔 — reference bit = 0 그리고 dirty bit = 0인 페이지. 최근에 안 쓴 clean 페이지. 가장 싼 축출.
- 2순위 스캔 — reference bit = 0 그리고 dirty bit = 1인 페이지. 최근에 안 쓴 dirty 페이지. 1순위가 없을 때만 선택.
같은 결정을 내리는 데 비트 한 개를 더 추가해서 디스크 I/O를 한 번 절약한 셈이다. 가상 메모리 시스템 전체가 이런 작은 비트와 큰 절약의 교환들로 채워져 있다는 점이 이번 시리즈가 반복해서 보여주는 패턴이다.
시야 확장 — VM의 다른 정책들
페이지 교체가 가장 중요한 정책이지만 유일한 건 아니다. VM 서브시스템에는 다른 결정들이 함께 작동한다.
페이지 선택 정책 — 언제 가져올 것인가
지금까지 다룬 흐름 — 접근이 일어났을 때 비로소 페이지를 디스크에서 가져오는 — 이 demand paging이다. 1970년 Denning이 이름 붙였고 대부분의 OS가 채택한 기본 방식이다. 실제 필요한 페이지만 메모리에 두니 효율적이다.
그러나 OS가 미래의 접근을 합리적으로 추측할 수 있는 경우엔 미리 가져올 수도 있다. 이게 prefetching이다. 가장 흔한 사례 — 코드 페이지 P가 적재되면 P+1도 함께 가져온다. 순차적 코드 실행이라는 공간적 지역성에 베팅한 것이다.
prefetching은 맞으면 절약이고 틀리면 낭비다. 예측이 맞으면 폴트 한 번을 면하지만, 틀리면 안 쓸 페이지를 위해 메모리와 I/O를 썼다. 그래서 성공 가능성이 합리적일 때만 한다. 무작정 예측해 가져오는 prefetching은 시스템 전체를 느리게 만들 수 있다.
페이지 쓰기 정책 — 어떻게 내보낼 것인가
축출되는 dirty 페이지를 한 번에 하나씩 디스크에 쓰면 비효율적이다. 디스크는 작은 쓰기 여러 번보다 큰 쓰기 한 번이 훨씬 빠르니까 — 탐색·회전 오버헤드가 한 번에 분산된다.
그래서 OS는 dirty 페이지들을 모았다가 한 번에 쓴다 — clustering 또는 grouping. 3편의 페이지 데몬 섹션에서 이미 본 그 최적화다. 4편 관점에서 보면 이게 쓰기 정책의 한 형태 — 축출 정책이 무엇을 내보낼지를 정한다면, 쓰기 정책은 어떻게 모아 내보낼지를 정한다.
스래싱과 그 대응
워크로드의 총 작업 집합(working set) — 활발히 쓰이는 페이지들의 합 — 이 물리 메모리 크기를 초과하면 시스템은 곤란해진다. 폴트가 끊임없이 발생하고, 막 들여온 페이지가 다음 순간 또 축출된다. 새 페이지를 들이느라 옛 페이지를 내보내고, 그 옛 페이지가 다시 필요해지고 — 정책이 무엇이든 무한 사이클이다. 이 상태를 스래싱(thrashing) 이라 한다. CPU의 대부분이 유용한 작업이 아니라 페이지 교체에 쓰인다.
전통적 대응은 admission control — 프로세스의 일부를 의도적으로 중단해서 활성 working set을 메모리에 맞게 줄인다. "전부를 잘못하느니 일부만 잘하자"는 철학. 짧게 줄어들고 짧게 회복되는 자연스러운 사이클이 가능해진다.
리눅스의 현대적 대응은 더 거칠다 — OOM(Out-of-Memory) killer. 메모리 압박이 임계점을 넘으면 가장 메모리를 많이 쓰는 프로세스를 골라 그냥 죽인다. 단순하고 빠르지만 부작용이 명확하다. 중요한 프로세스가 종료될 위험이 있다. X 서버가 OOM 대상이 되어 모든 GUI 애플리케이션이 함께 사라지는 사고가 종종 있다. 정교한 admission control 대신 급진적 회복을 택한 트레이드오프다.
시리즈 마무리
1부는 페이징을 도착점으로 두고 세그멘테이션의 외부 단편화 문제를 해결했다. 동시에 두 문제를 남겼다. 변환의 속도가 두 배로 느려졌고, 페이지 테이블 자체의 크기가 4MB 단위로 커졌다.
2부는 그 둘을 해결했다. TLB가 캐싱으로 변환 속도를 회복했고, 멀티레벨 페이지 테이블이 트리 구조로 페이지 테이블 자체의 크기를 압축했다. 캐싱과 시간-공간 교환 — 1편에서 본 자료구조의 두 trade-off가 양쪽 다 회수됐다.
3부는 1편부터 깔려 있던 가정 하나를 풀었다 — "모든 페이지가 메모리에 있다." 스왑 공간과 present bit과 페이지 폴트 메커니즘으로, 메모리는 디스크의 캐시가 됐다. 가상 메모리가 비로소 "메모리보다 큰 메모리"라는 이름값을 한다.
4부는 그 캐시 위에서 작동하는 정책을 다뤘다. 미래를 모르는 채로 과거 정보로 어디까지 근사할 수 있는지 — OPT부터 LRU, Clock까지의 진화는 지역성이라는 단 하나의 가정 위에서 이뤄졌다. 가상 메모리는 지역성을 끝까지 짜내는 시스템이다.
자료구조의 관점에서 보면 시리즈 전체가 일관된 결을 띤다. 1편의 페이지 테이블 = 자료구조 선택의 자유, 2부의 TLB = 캐싱과 멀티레벨 = 트리, 3부의 present bit + PFN 필드 재활용, 4부의 use bit + dirty bit. 모두 작은 부품의 정교한 조합으로 큰 문제를 푼다.
가상 메모리는 모든 현대 OS가 당연한 듯이 제공하는 기능이지만, 그 안에는 50년 가까운 진화의 결과가 들어 있다. 페이징·세그멘테이션의 초기 아이디어부터 TLB·멀티레벨·페이지 폴트·Clock 근사까지, 작동하는 추상화가 어떻게 다듬어졌는지를 한 흐름으로 본 셈이다.
VirtualMemory Paging PageReplacement LRU Clock OSTEP CSAPP 정글 입문
'OS' 카테고리의 다른 글
| 가상 메모리 ③ — 스와핑과 페이지 폴트 (0) | 2026.05.29 |
|---|---|
| 가상 메모리 ② — TLB와 멀티레벨 페이지 테이블 (0) | 2026.05.29 |
| 가상 메모리 ① — 주소 공간에서 페이징까지 (0) | 2026.05.29 |
| CPU 스케줄링 (0) | 2026.05.28 |
| 프로세스 vs 스레드 (1) | 2026.05.28 |